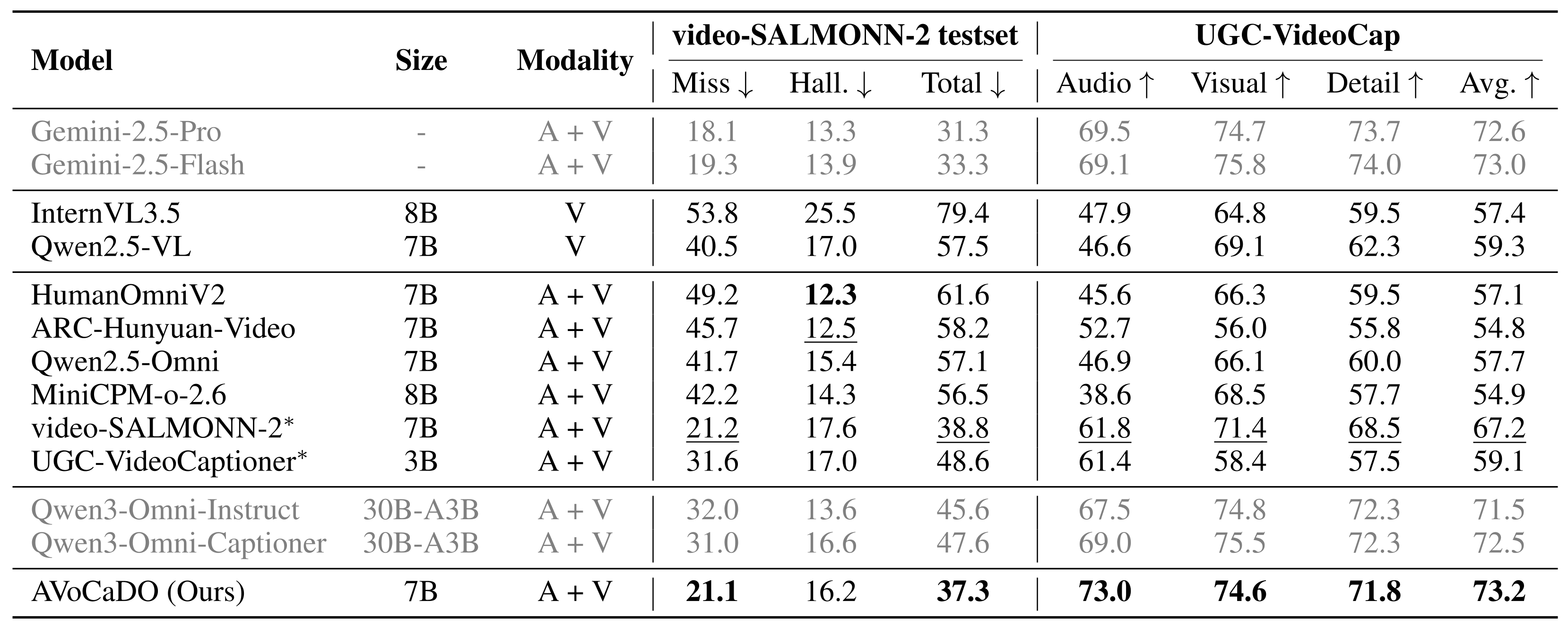
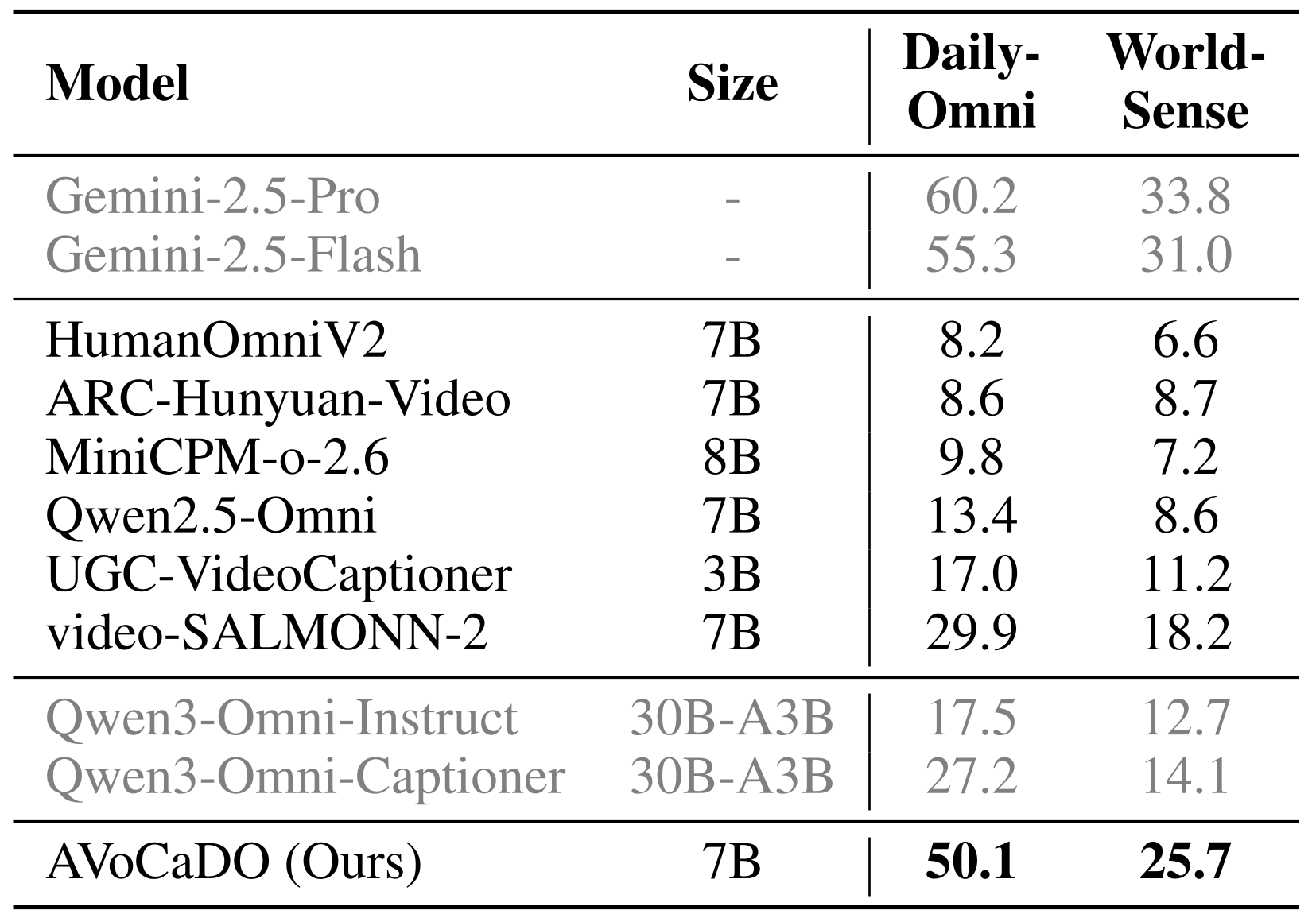
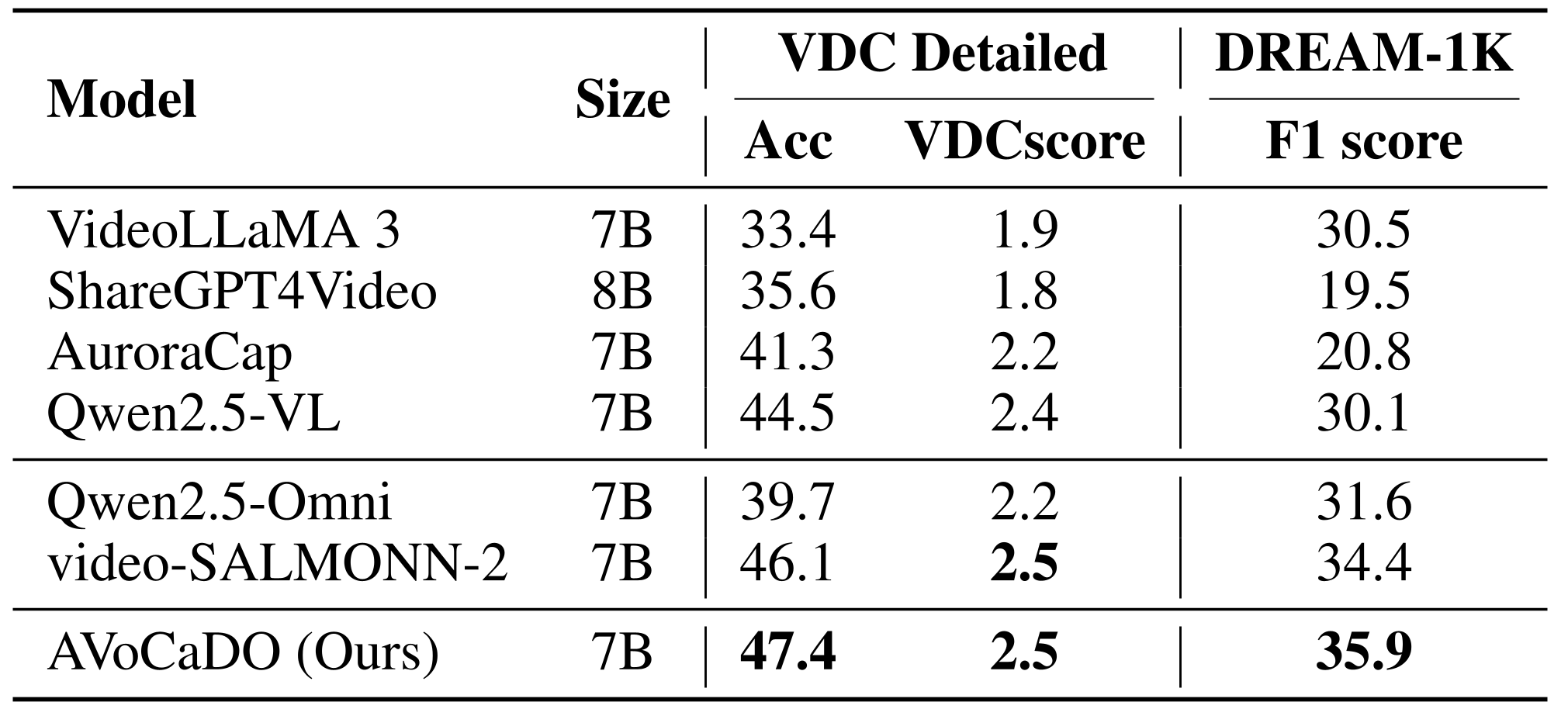
Full caption:
The audio begins with the loud, enthusiastic sound of a crowd cheering and clapping. A man with a deep, energetic voice exclaims, "Give it up for Marlon Wayans!" The crowd's applause and excited shouts continue in the background. The video opens with a medium shot of two men standing in the center of a crowd outdoors. The man on the left, who is Black and wearing a light blue button-down shirt and sunglasses, gestures with his hands as he speaks. The man on the right, who is white with a beard and sunglasses, wears a black polo shirt and gestures emphatically with his hands while looking at the other man. The crowd, a mix of men and women, surrounds them, clapping and watching with interest. The setting is a bright, sunny day in what appears to be an urban plaza, with palm trees and buildings visible in the background. A red banner with white text is partially visible on the left. The camera remains steady, capturing the interaction between the two main subjects and the engaged audience.
The man with the beard speaks with a friendly and slightly breathless tone, "Alright, guys. So, it's hot. I want to do a trick with some money. You got your wallet?" The man in the blue shirt replies calmly, "Yeah, I got my wallet." "Alright, let me see it," the bearded man requests. "Alright," the other man agrees. The bearded man continues in a confident, instructional voice, "Cuz usually anytime you you grab money or... Wow. Okay, yeah. Alright, let's just do this. Anytime you grab for money, the number one thing when a magician grabs a dollar bill, what do they say?" The man in the blue shirt responds with a slightly confused and humorous tone, "I don't know, bro. I know a brother said, 'Give me my money back.'" The bearded man laughs lightly and continues, "Okay. Well, I tell you what, a lot of people say, 'Can you take that one and turn it into a hundred?'" "Okay," the other man agrees. "I'm not that good," the bearded man concedes. "So what I tell people is if you can just cut your expectation in half, I'll blow you away. So when I say in half, I literally mean in half. And we can take that one and turn it into a fifty." The camera zooms in for a close-up on the hands of the man in the black shirt. He holds a small, folded fifty-dollar bill between his fingers, displaying it to the crowd. The faces of the onlookers, including a woman with long dark hair, are visible in the blurred background, looking on with curiosity. The man unfolds the bill, revealing it to be a single dollar bill. He then folds it in half, and then in half again, demonstrating the size difference. The camera angle shifts slightly, showing the man continuing to manipulate the dollar bill, folding it into an even smaller rectangle. The crowd remains in the background, their faces a mix of anticipation and excitement. "See what I mean?" "Wow, that works," the man in the blue shirt says, sounding impressed. "Well, but but you still want to see the hundred, right?" the bearded man asks, his voice full of energy. "Yes," the other man confirms. "Cuz everybody wants to see the hundred. So that's when you take it this way, and sure enough, my man, we can take the one into a fifty into a hundred. You and I need to go into business together, man. Let's do it." The camera pulls back to the original medium shot. The man in the black shirt, now holding the folded dollar bill, gestures towards the man in the blue shirt. The crowd erupts in cheers and applause, with many people raising their hands and clapping enthusiastically. The man in the blue shirt smiles and gestures with open hands, looking pleased. The bearded man exclaims, "Take a dollar! Take a dollar! Take a dollar to a hundred! We're gonna be rich! Take a dollar! We're gonna be rich!" The crowd's cheers and applause swell in response. The man in the black shirt then turns and moves through the cheering crowd, who are now clapping and celebrating. The man in the blue shirt remains in the center, smiling and gesturing towards the camera. The bearded man continues to interact with the audience, pointing and gesturing energetically. The scene is filled with the sounds of celebration and excitement.
The video transitions to a black screen with a central, framed video window. Inside the window, a bald man with glasses and a black shirt is shown sitting in front of a red curtain, smiling and speaking directly to the camera. To the left of the window, the text "EPISODES & CLIPS" and "WATCH MORE" appears. Below the window, the word "SUBSCRIBE" is displayed. The background is dark with subtle, sparkling light effects. The audio then transitions to a different man speaking in a friendly and upbeat voice, as if addressing an online audience. "Hey YouTube, thanks for watching. If you like this and you want to see a lot more, all you got to do is click right here to subscribe." The man in the video window gestures with his hand as he speaks, concluding his message. The on-screen text and graphics remain the same.
 AVoCaDO: An AudioVisual Video Captioner Driven by Temporal Orchestration
AVoCaDO: An AudioVisual Video Captioner Driven by Temporal Orchestration